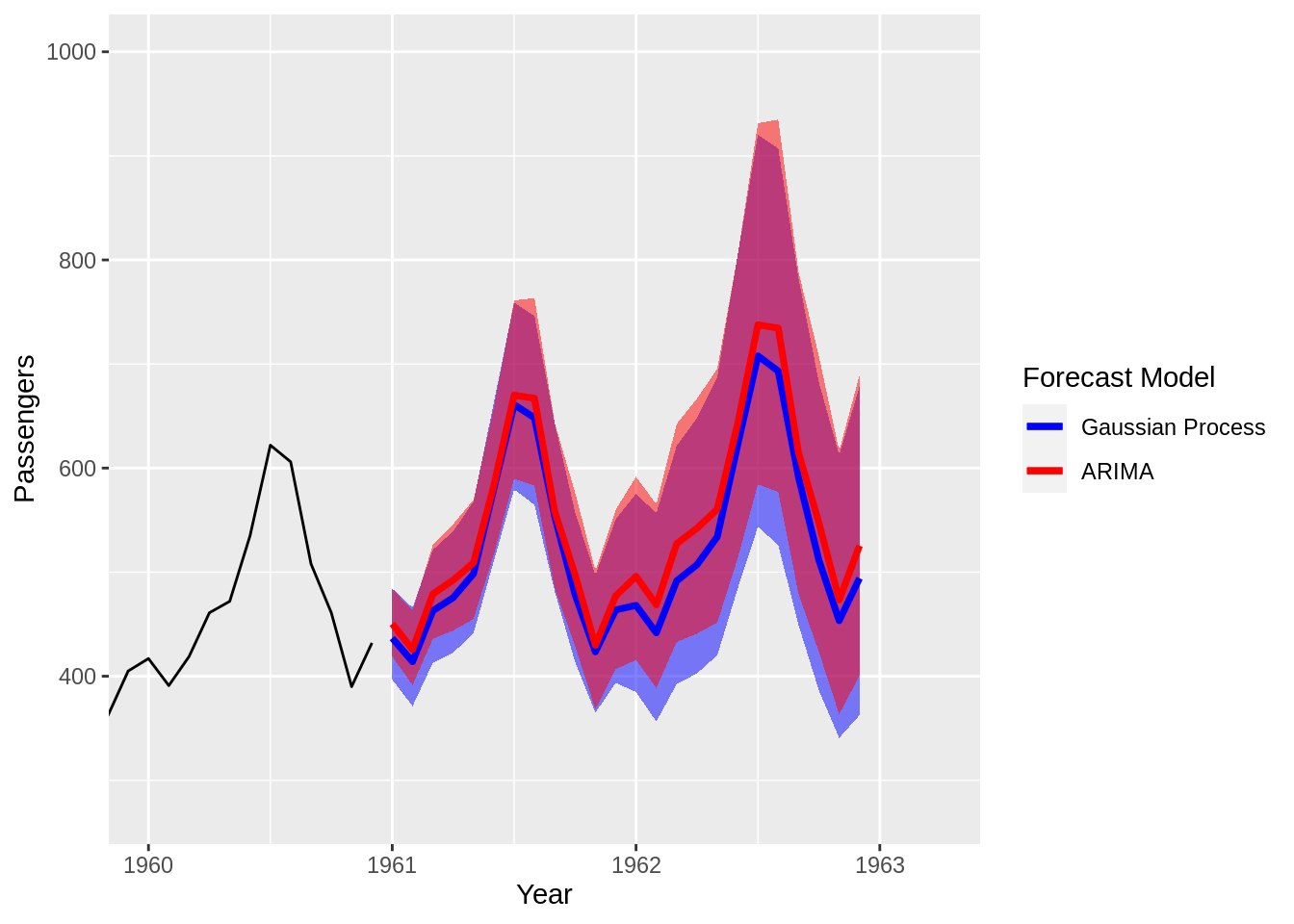
Gaussian Process Imputation/Forecast Models
(Updated: 2020-12-31) Problem Statement Create a forecast model using only the information available in a single, univariate time series. The Past is Prologue Sometimes the only data we have to predict a particular phenomenon are previous measurements of the target variable we hope to forecast. Using the past to predict the future means that we assume prior trends will continue into the forecast window. Absent other information and all else being equal, making a past is prologue assumption is not a terrible decision in many cases.